PDF] ELF OpenGo: An Analysis and Open Reimplementation of AlphaZero
Por um escritor misterioso
Last updated 14 novembro 2024
![PDF] ELF OpenGo: An Analysis and Open Reimplementation of AlphaZero](https://d3i71xaburhd42.cloudfront.net/1660a5d34d5fb237b8d64d292c4f360bc70252be/5-Figure1-1.png)
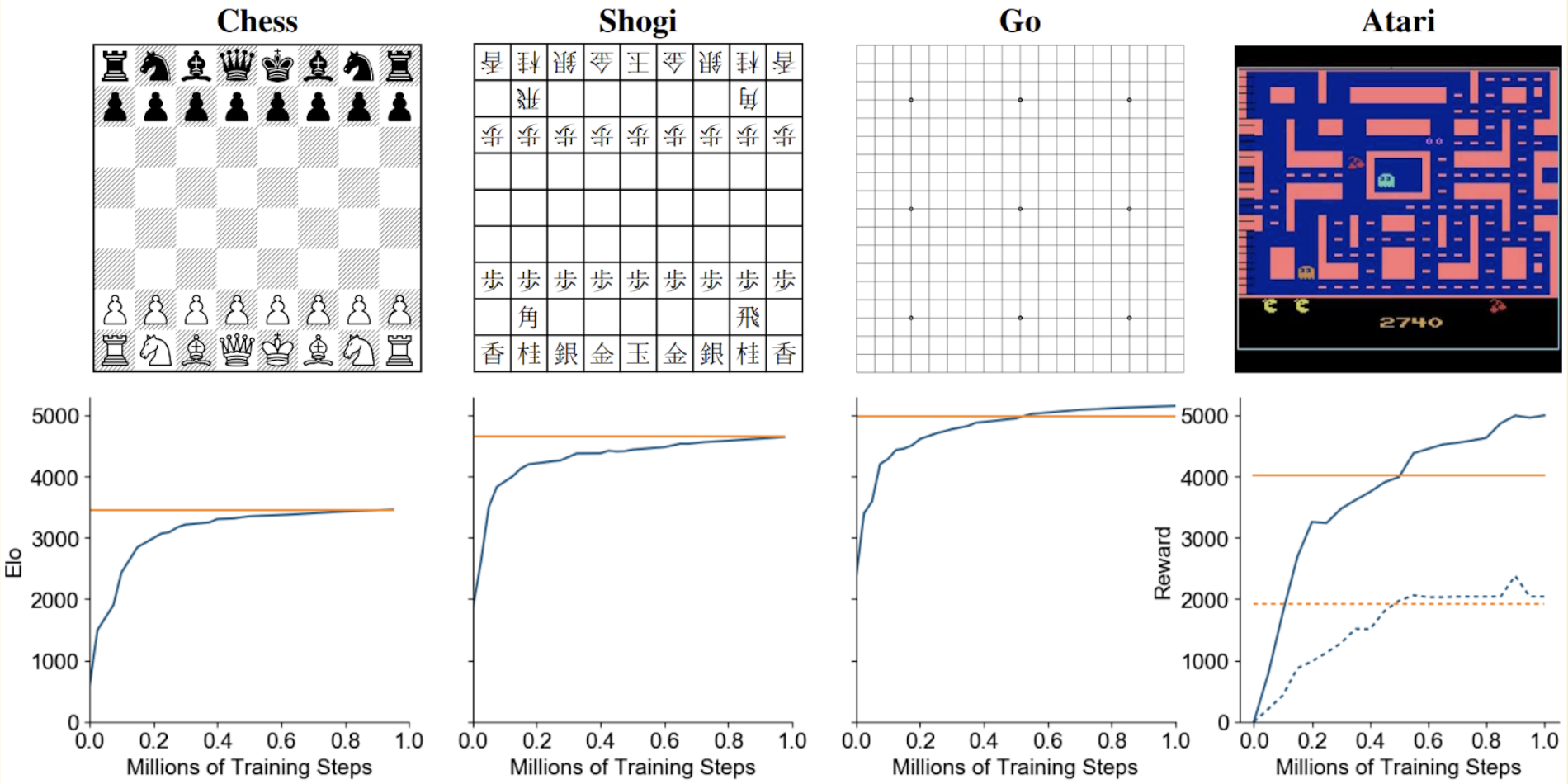
ELF OpenGo is the first open-source Go AI to convincingly demonstrate superhuman performance with a perfect (20:0) record against global top professionals and is proposed, anopen-source reimplementation of the AlphaZero algorithm. The AlphaGo, AlphaGo Zero, and AlphaZero series of algorithms are remarkable demonstrations of deep reinforcement learning's capabilities, achieving superhuman performance in the complex game of Go with progressively increasing autonomy. However, many obstacles remain in the understanding of and usability of these promising approaches by the research community. Toward elucidating unresolved mysteries and facilitating future research, we propose ELF OpenGo, an open-source reimplementation of the AlphaZero algorithm. ELF OpenGo is the first open-source Go AI to convincingly demonstrate superhuman performance with a perfect (20:0) record against global top professionals. We apply ELF OpenGo to conduct extensive ablation studies, and to identify and analyze numerous interesting phenomena in both the model training and in the gameplay inference procedures. Our code, models, selfplay datasets, and auxiliary data are publicly available.
![PDF] ELF OpenGo: An Analysis and Open Reimplementation of AlphaZero](https://d3i71xaburhd42.cloudfront.net/3d5a107d0f9803e450bee409491b5a54f25b0d7a/8-Table7-1.png)
PDF] Brick Tic-Tac-Toe: Exploring the Generalizability of AlphaZero to Novel Test Environments
PDF] ELF OpenGo: An Analysis and Open Reimplementation of AlphaZero
![PDF] ELF OpenGo: An Analysis and Open Reimplementation of AlphaZero](https://d3i71xaburhd42.cloudfront.net/8044f20dc1d257b6790abeddb08be96861c2d0ee/3-Figure2-1.png)
PDF] From Gameplay to Symbolic Reasoning: Learning SAT Solver Heuristics in the Style of Alpha(Go) Zero
![PDF] ELF OpenGo: An Analysis and Open Reimplementation of AlphaZero](https://d3i71xaburhd42.cloudfront.net/f244ffb549a61806d00f614e70fa1c3fbe5fffc6/9-Figure4-1.png)
PDF] Accelerating Self-Play Learning in Go
![PDF] ELF OpenGo: An Analysis and Open Reimplementation of AlphaZero](https://images.deepai.org/publication-preview/elf-opengo-an-analysis-and-open-reimplementation-of-alphazero-page-7-medium.jpg)
ELF OpenGo: An Analysis and Open Reimplementation of AlphaZero
![PDF] ELF OpenGo: An Analysis and Open Reimplementation of AlphaZero](https://ars.els-cdn.com/content/image/1-s2.0-S0004370223000838-gr020.jpg)
Spatial state-action features for general games - ScienceDirect
![PDF] ELF OpenGo: An Analysis and Open Reimplementation of AlphaZero](https://d3i71xaburhd42.cloudfront.net/c2307ee6be72a42678feff85b8abf8a66f836160/9-Figure4-1.png)
PDF] Improving Model and Search for Computer Go
![PDF] ELF OpenGo: An Analysis and Open Reimplementation of AlphaZero](https://ars.els-cdn.com/content/image/1-s2.0-S2590005622000133-fx2a.jpg)
A survey of deep reinforcement learning application in 5G and beyond network slicing and virtualization - ScienceDirect
![PDF] ELF OpenGo: An Analysis and Open Reimplementation of AlphaZero](https://gwern.net/doc/reinforcement-learning/model/alphago/2022-mcgrath-figure5-b-alphazeroopeningmoveovertraininghistory.png)
AlphaGo tag ·
![PDF] ELF OpenGo: An Analysis and Open Reimplementation of AlphaZero](https://www.researchgate.net/publication/335683302/figure/fig1/AS:962426002485248@1606471648017/OpenGo-Darkforest-OGD-cloud-platform-with-a-BCI-application_Q320.jpg)
Intelligent agent for real-world applications on robotic edutainment and humanized co-learning
![PDF] ELF OpenGo: An Analysis and Open Reimplementation of AlphaZero](https://gwern.net/doc/reinforcement-learning/model/alphago/2023-zahavy-figure7-scalingofchesspuzzlesolutionswithmultiplealphazeroagentsandsimulations.png)
AlphaGo tag ·
![PDF] ELF OpenGo: An Analysis and Open Reimplementation of AlphaZero](https://d3i71xaburhd42.cloudfront.net/f1969fb1c9831689d7e7f2eeefa8192b97600ce1/4-Figure1-1.png)
PDF] Mobile Networks for Computer Go
![PDF] ELF OpenGo: An Analysis and Open Reimplementation of AlphaZero](http://res.cloudinary.com/cea/image/upload/v1671700621/mirroredImages/pZPDQmyEoaqBB8szD/z2lqcccz7bovviz2pa7p.png)
Conclusion and Bibliography for “Understanding the diffusion of large language models” — Rethink Priorities
![PDF] ELF OpenGo: An Analysis and Open Reimplementation of AlphaZero](https://d3i71xaburhd42.cloudfront.net/f244ffb549a61806d00f614e70fa1c3fbe5fffc6/12-Table2-1.png)
PDF] Accelerating Self-Play Learning in Go
Recomendado para você
-
 The future is here – AlphaZero learns chess14 novembro 2024
The future is here – AlphaZero learns chess14 novembro 2024 -
 Revista de Xadrez New In Chess 2019-8 Magnus Carlsen Observe as Fotos14 novembro 2024
Revista de Xadrez New In Chess 2019-8 Magnus Carlsen Observe as Fotos14 novembro 2024 -
GitHub - AlSaeed/AlphaZero: An Implementation of the AlphaZero Paper14 novembro 2024
-
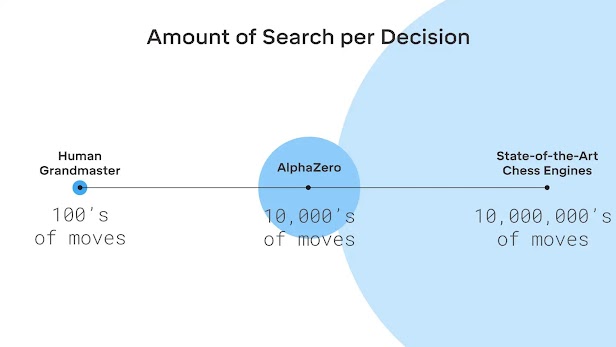
 The Data Problem III: Machine Learning Without Data - Synthesis AI14 novembro 2024
The Data Problem III: Machine Learning Without Data - Synthesis AI14 novembro 2024 -
 Question on the Alpha Zero research paper : r/chess14 novembro 2024
Question on the Alpha Zero research paper : r/chess14 novembro 2024 -
 DeepMind: the existence proof for RL at scale, by Nathan Lambert14 novembro 2024
DeepMind: the existence proof for RL at scale, by Nathan Lambert14 novembro 2024 -
 Zero-Alpha. NZ Police Armed Offenders Squad Official History. By Ray V – Phoenix Books NZ14 novembro 2024
Zero-Alpha. NZ Police Armed Offenders Squad Official History. By Ray V – Phoenix Books NZ14 novembro 2024 -
AlphaZero: Shedding new light on chess, shogi, and Go - Google14 novembro 2024
-
 A general reinforcement learning algorithm that masters chess, shogi, and Go through self-play14 novembro 2024
A general reinforcement learning algorithm that masters chess, shogi, and Go through self-play14 novembro 2024 -
![PDF] Reproducibility via Crowdsourced Reverse Engineering: A](https://d3i71xaburhd42.cloudfront.net/307af86b352c73a2450fd8ceef70948531062eb0/3-Figure1-1.png) PDF] Reproducibility via Crowdsourced Reverse Engineering: A14 novembro 2024
PDF] Reproducibility via Crowdsourced Reverse Engineering: A14 novembro 2024
você pode gostar
-
 LEGO Sonic the Hedgehog Oficina do Tails e Avião - Tornado 76991 376 Peças - Brinquedos de Montar e Desmontar - Magazine Luiza14 novembro 2024
LEGO Sonic the Hedgehog Oficina do Tails e Avião - Tornado 76991 376 Peças - Brinquedos de Montar e Desmontar - Magazine Luiza14 novembro 2024 -
 CapCut_how to view twitter protected tweets14 novembro 2024
CapCut_how to view twitter protected tweets14 novembro 2024 -
 Pokemon Emerald Ruby Platinum Heart Gold Black2 5set Nintendo GBA DS Japanese14 novembro 2024
Pokemon Emerald Ruby Platinum Heart Gold Black2 5set Nintendo GBA DS Japanese14 novembro 2024 -
 Mechas 3D: Fazer ou não fazer? - London Cosméticos14 novembro 2024
Mechas 3D: Fazer ou não fazer? - London Cosméticos14 novembro 2024 -
 Please Donate Sign by TransmitingPoint2You on DeviantArt14 novembro 2024
Please Donate Sign by TransmitingPoint2You on DeviantArt14 novembro 2024 -
 Generational chart of Pokemon Legendaries : r/gaming14 novembro 2024
Generational chart of Pokemon Legendaries : r/gaming14 novembro 2024 -
 Love, Chunibyo & Other Delusions! Heart Throb14 novembro 2024
Love, Chunibyo & Other Delusions! Heart Throb14 novembro 2024 -
 Insomniacs After School (Volume) - Comic Vine14 novembro 2024
Insomniacs After School (Volume) - Comic Vine14 novembro 2024 -
 Dawn in Team Galactic? 10 Odd Facts About Pokémon Evil Teams14 novembro 2024
Dawn in Team Galactic? 10 Odd Facts About Pokémon Evil Teams14 novembro 2024 -
 Free STL file Flowey Undertale Figure 🎲・3D print design to download・Cults14 novembro 2024
Free STL file Flowey Undertale Figure 🎲・3D print design to download・Cults14 novembro 2024